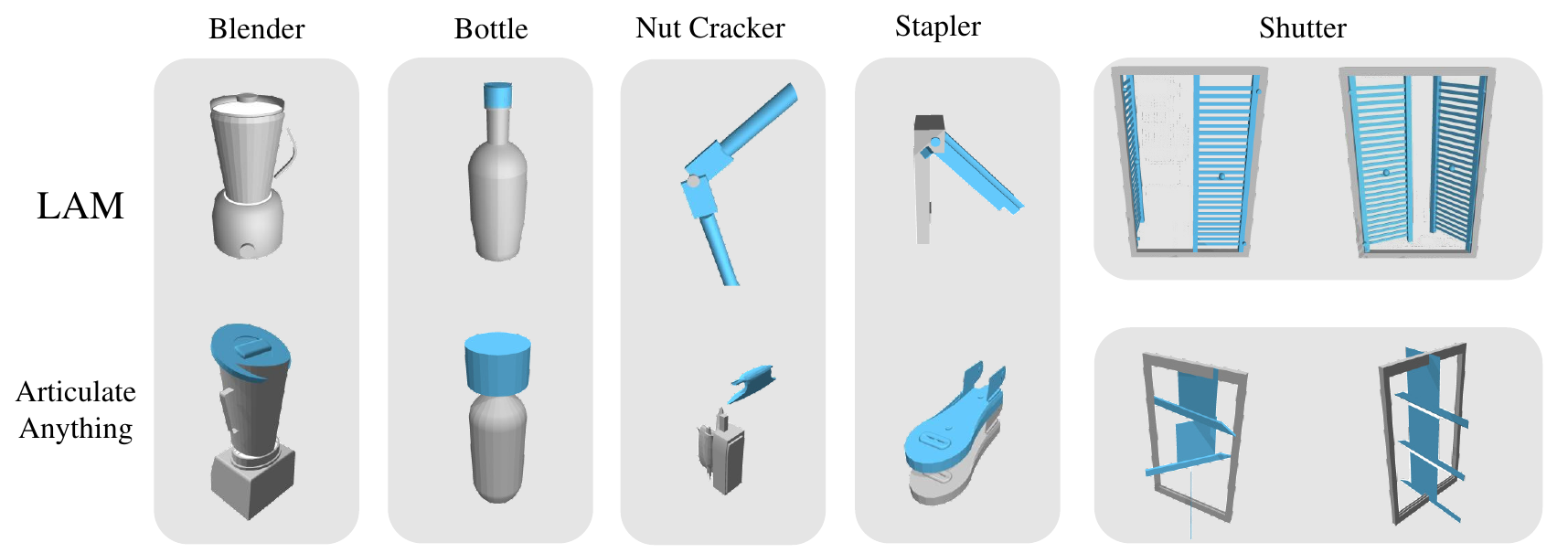
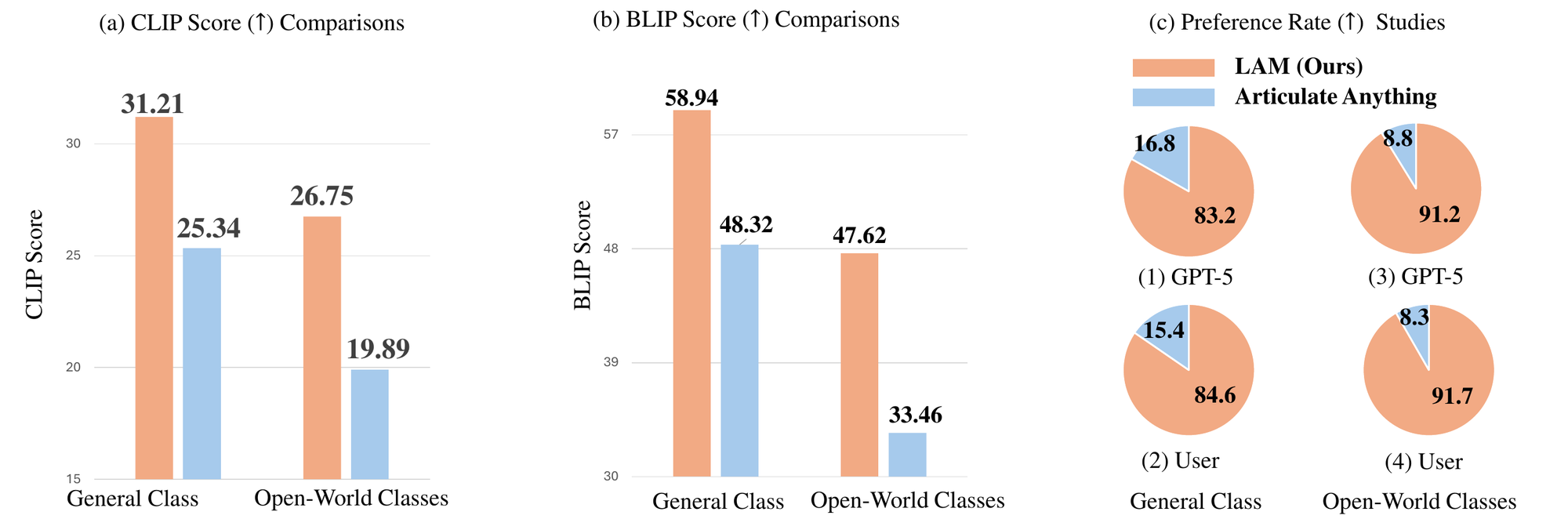
We introduce LAM, a system that explores the collaboration between
large language models and vision-language models to generate articulated objects from text
prompts without a visual prior or pre-built 3D assets. We formulate articulated object
generation as a unified code-generation task, in which geometry and articulation are
co-designed from scratch.
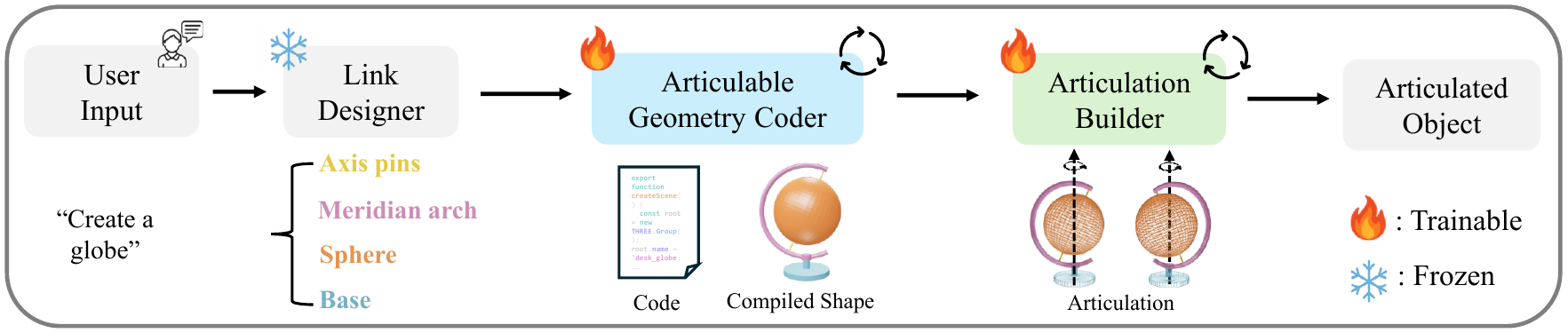
Given an input text, LAM coordinates a team of specialized modules
to procedurally generate code that represents the desired articulated object. It first reasons
about the hierarchical structure of parts (links) with a Link Designer, then writes,
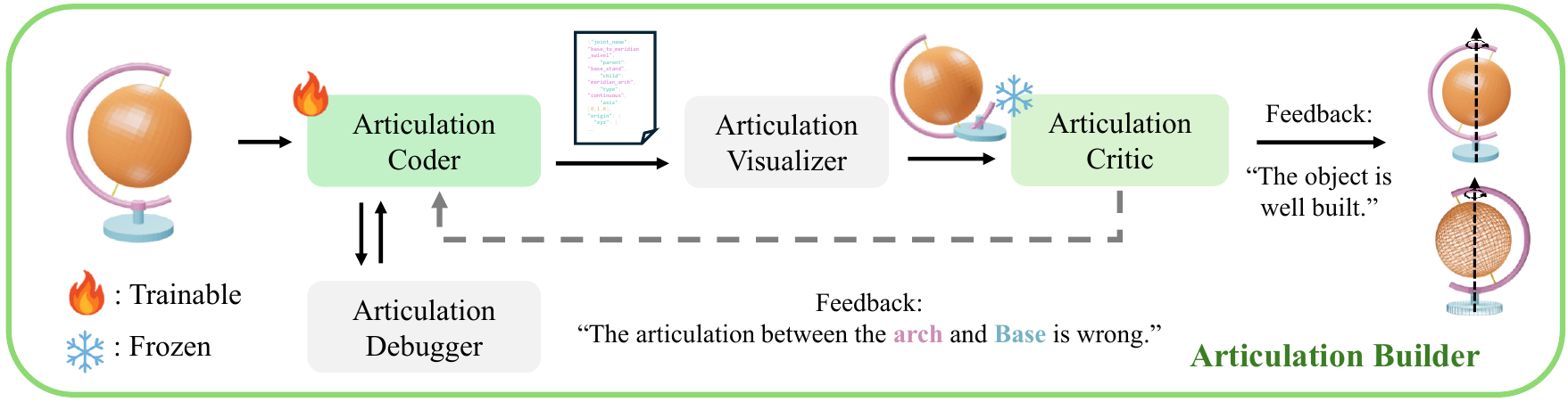
compiles, and debugs code with Geometry & Articulation Coders, and self-corrects via
Geometry & Articulation Checkers. The code serves as a structured, interpretable bridge
between individual links, ensuring correct relationships among them.
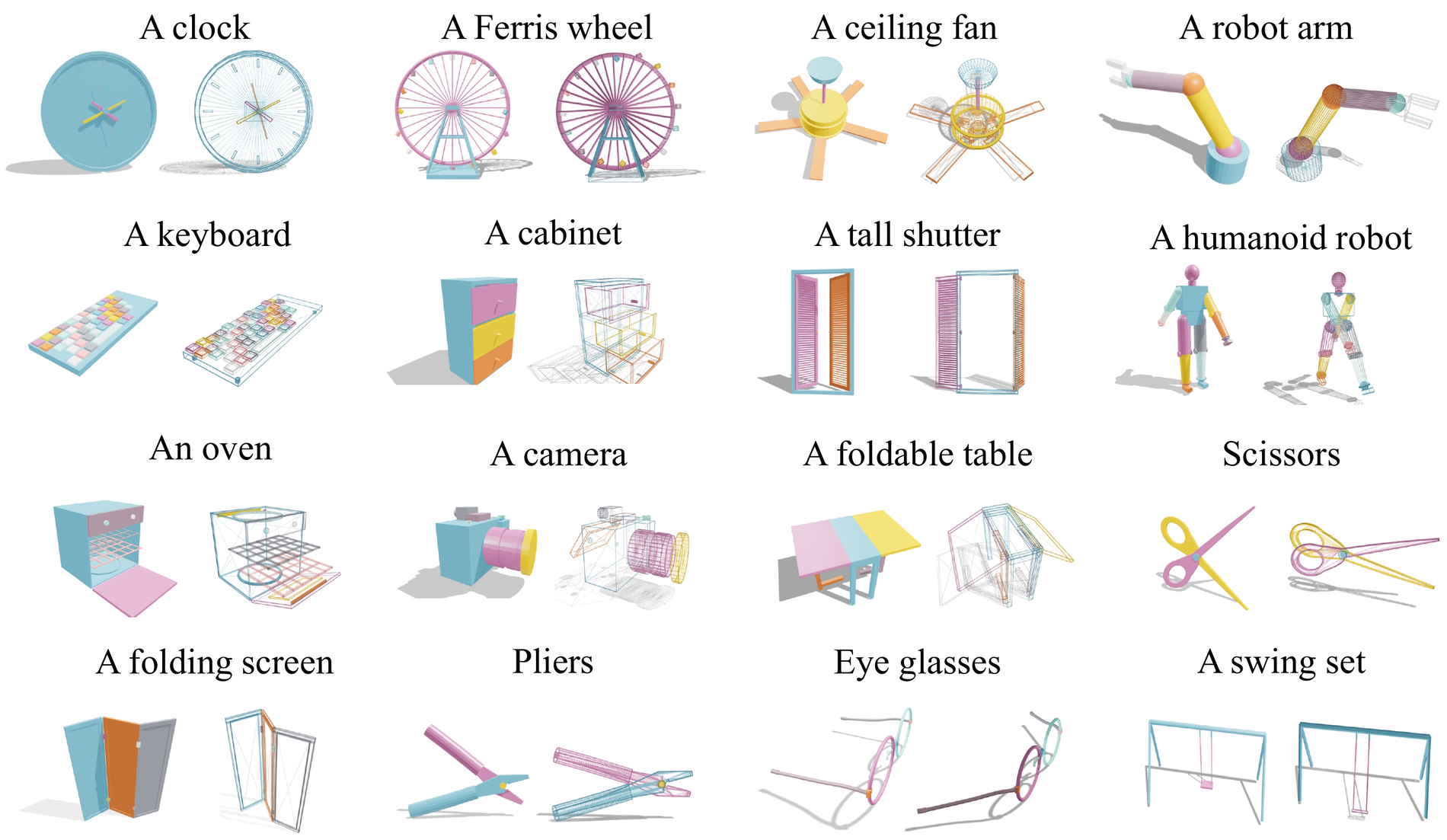
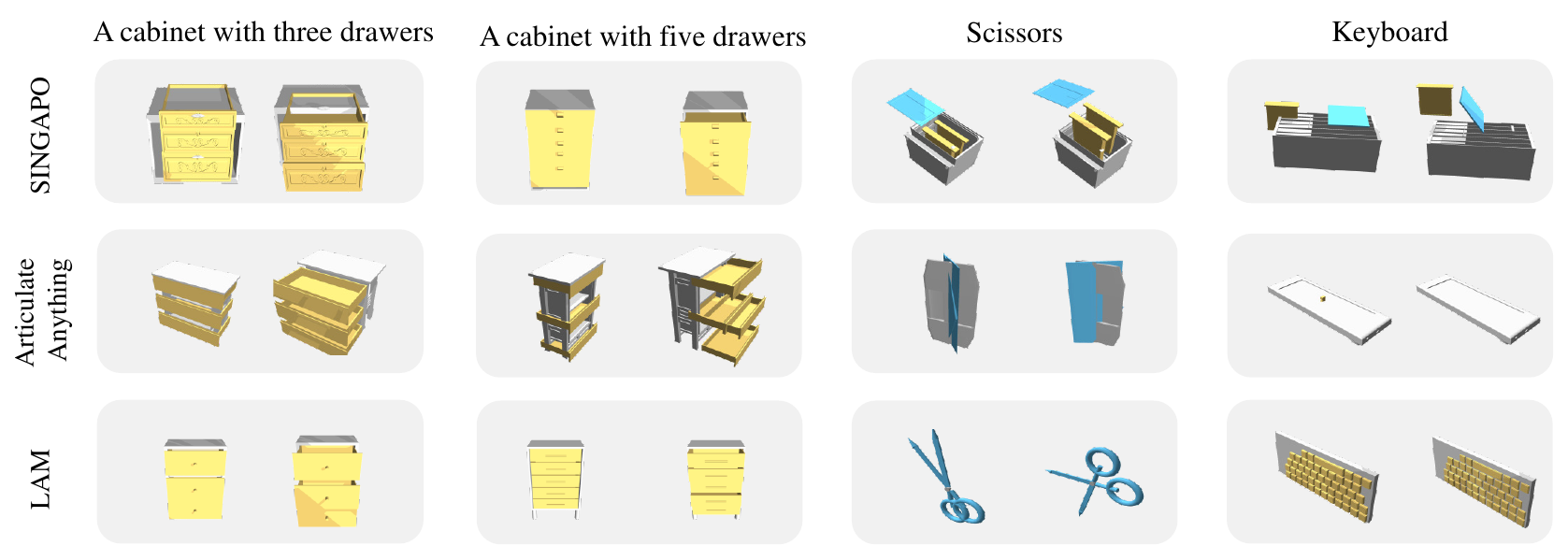
Experiments demonstrate the power of leveraging code as a generative medium within a collaborative
system, showcasing its effectiveness in automatically constructing complex articulated objects.